The Semantic Graph Platform
Timbr is an ontology-based semantic layer that provides a semantic context layer for enterprise AI and analytics systems.
It creates a virtual knowledge graph over existing data sources using SQL-native ontologies, allowing organizations to define business entities, relationships, and logic directly on top of their data without moving or duplicating it.
The platform integrates with existing databases and tools, enabling consistent and governed access to data across SQL queries, BI tools, and AI systems.
Note: Timbr does not store your data. It creates a virtual layer that connects directly to your existing data sources, allowing you to query, model, and analyze without moving or duplicating your data.
For installation instructions and getting started with Timbr, see the Installation & Configuration guide. To understand core concepts and terminology, refer to the Introduction to Timbr.
Architecture
Timbr is accessible using JDBC, ODBC, REST API:
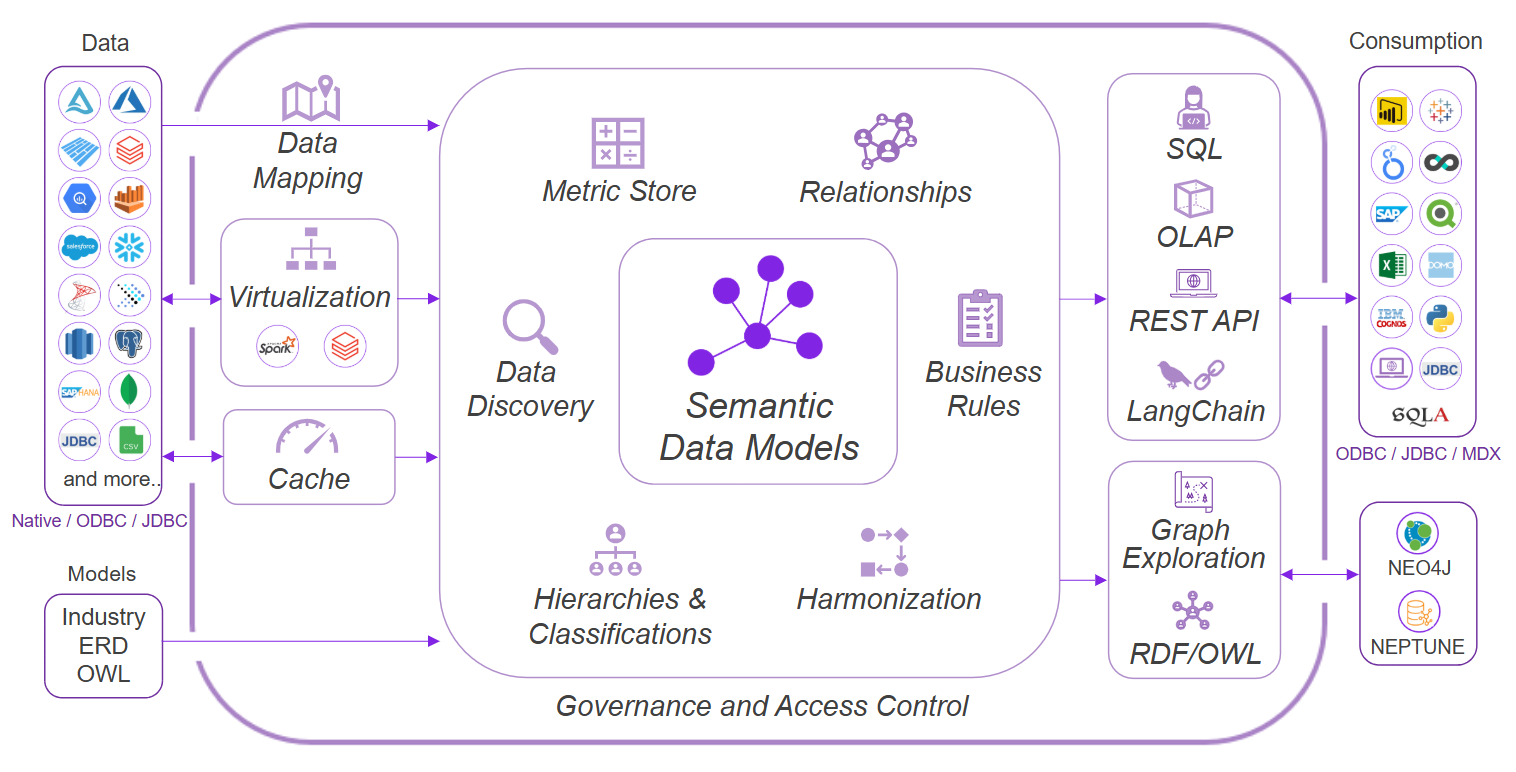
For detailed information on connecting external tools and applications to Timbr, see the Integration documentation.
Main Components
Model
Visualize
Manage
- Manage Knowledge Graphs
- Datasources
- Large Language Models
- Data Agents
- Benchmarks
- Scheduled Jobs
- Access Manager
- Recent Activity
SQL Lab
Getting Started Resources:
- Ontology Modeling Tutorial - Comprehensive guide to creating concepts, relationships, and mappings
- Querying Knowledge Graphs - Learn to write SQL queries against your semantic model
- Telecommunications Use Case - Complete tutorial building a Telecommunications knowledge graph from scratch
- Supply Chain Use Case - Complete tutorial building a Supply Chain knowledge graph from scratch
Integration Guides:
- BI Tools - Connect Power BI, Tableau, and other visualization tools
- Python Integration - Use Timbr with Python applications
- LLM Integrations - Connect with LangChain and other AI frameworks
- Databricks Integration - Leverage Timbr's semantic lakehouse approach
- Microsoft Excel - Connect Excel for data analysis and reporting
Features
- Ontology Modeling: represent an abstract, simplified view of the world with conceptual schemas.
- Business Rules: embed business logic and rules into the data model.
- Virtualization: no ETL required. Distributed JOINs/UNIONs and Push-down optimizations.
- Graph Traversals: graph traversals in standard SQL without the need to explicitly write joins.
- Inheritance: is-a relationships provides higher level of abstraction than SQL views.
- Inference: infer new knowledge and relationships based on a set of rules on the data.
- Graph Exploration: an intuitive interface for exploring and visualizing data.
- NoSQL Capabilities: allowing a relatively flexible schema declaration and evolution.
- Integration: supports most SQL Engines, NoSQL, and data formats.
- Materialization: 4-tier cache engine - Database, Datalake, SSD, OLAP In-memory.
- Apache Spark and Databricks Native: available in DataFrames on Java, Scala, R and Python.