Install
Timbr Integrations with Databricks:
- You can configure Databricks in Timbr as a datsource (with optional virtualization).
- You can install Timbr inside Unity Catalog / Hive metastore to model and query your ontology.
Create Databricks datasource in Timbr
- Go to your Databricks Cluster configuration
Under Advanced Options -> select JDBC/ODBC -> Copy the JDBC URL:
jdbc:databricks://<hostname>:443/default;transportMode=http;ssl=1;httpPath=<http_path>;AuthMech=3;UID=token;
In your Timbr environment under Manage -> Datasources click on "Add new Datasource"
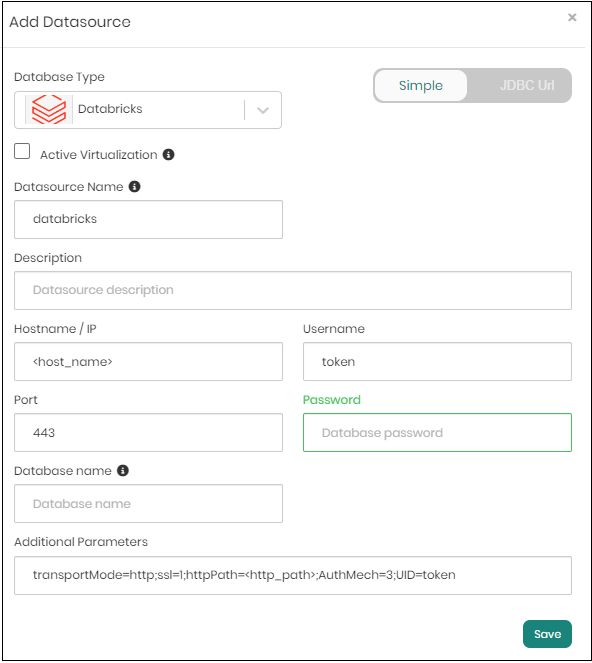
Fill in the following parameters:
- Datasource name
- Hostname: your Databricks hostname
- Port (default 443)
- Username: token
- Password: your Databricks personal access token
- Database name: default (optional)
- Additional Parameters: transportMode=http;ssl=1;httpPath=<http_path>;AuthMech=3;UID=token
Another option is the JDBC Url option in the "Add Datasource" window.
Copy and paste the Databricks JDBC:
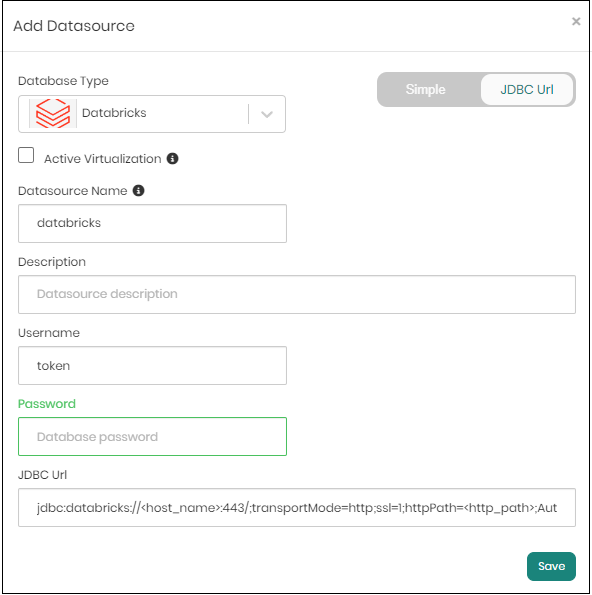
Two additional optional configuration options:
- Description - describe the purpose/usage of the datasource / cluster
- Active Virtualization - when enabling this option, Timbr will use the Databricks cluster to virtualize and join all other datasources defined in the ontology.
Install Timbr in your Databricks cluster
To install Timbr in your Databricks cluster, you need to setup the Timbr "init script" in your cluster.
You can find more information about Databricks init scripts at: https://docs.databricks.com/en/init-scripts
When installing Timbr using the init script, you can configure cluster-scoped init scripts and global init scripts. This means you can configure Timbr in a specific cluster (cluster-scoped) or by default on every cluster created in your workspace.
Timbr init script:
The Timbr init script installs the Timbr jar into your Databricks cluster. This enables Timbr to expose the ontology as part of the Unity Catalog / Hive metastore. It also allows users to use Timbr ontology DDL statements to create and manage the ontology.
The Timbr init script can be configured directly from your Databricks Workspace/DBFS/Volumes or from S3/ABFSS You can create it and set it up by yourself or use one from Timbr S3/ABFSS (contact Timbr support to get access).
The Timbr init script:
#!/bin/bash
mkdir -p /dbfs/FileStore/timbr/
curl -o /dbfs/FileStore/timbr/timbrsparkparser.jar "https://<timbr_url>/timbrsparkparser.jar"
cp /dbfs/FileStore/timbr/timbrsparkparser.jar /databricks/jars
The init script job is to copy the Timbr jar into Databricks jars.
To set it up yourself, go to your Databricks cluster configuration Advanced Options and select "Init Scripts".


For examples to setup the init script, you can follow the Databricks documentation (https://docs.databricks.com/en/init-scripts/global.html#add-a-global-init-script-using-the-ui) to setup the init-script globally.
Configure Timbr in Databricks
Once you've setup the init script, you can configure Timbr using the following Spark configuration (under Advanced options - Spark config):
| ConfigName | Options | Description |
|---|---|---|
| spark.sql.extensions | timbr.spark.TimbrSparkSession | Mandatory to enable Timbr in your Databricks cluster |
| spark.timbr.parse | true/false (default: true) | Enable/disable the Timbr SQL parser |
| spark.timbr.url | <timbr_hostname>:<timbr_port> | The hostname and port of your Timbr environment (port 443 for SSL, 80/11000 without SSL) |
| spark.timbr.ssl | true/false (default: false) | Connect to Timbr using SSL |
| spark.timbr.ontology | <ontology_name> | The ontology you want to connect |
| spark.timbr.user | token | The username to access the Timbr platform |
| spark.timbr.password | tk_12345678 | The Timbr token of the user |
| spark.timbr.sso | true/false (default: false) | Run queries in Timbr on behalf of the user authenticated in Databricks (the token used as password should be set with special auth permissions in Timbr) |
| spark.sql.catalog.spark_catalog | timbr.spark.TimbrCatalog | Optional configuration to enable Timbr under Hive metastore |
Once you configure Timbr, you can start querying your ontology directly from Databricks notebooks and explore the metadata in the Databricks Catalog explorer.