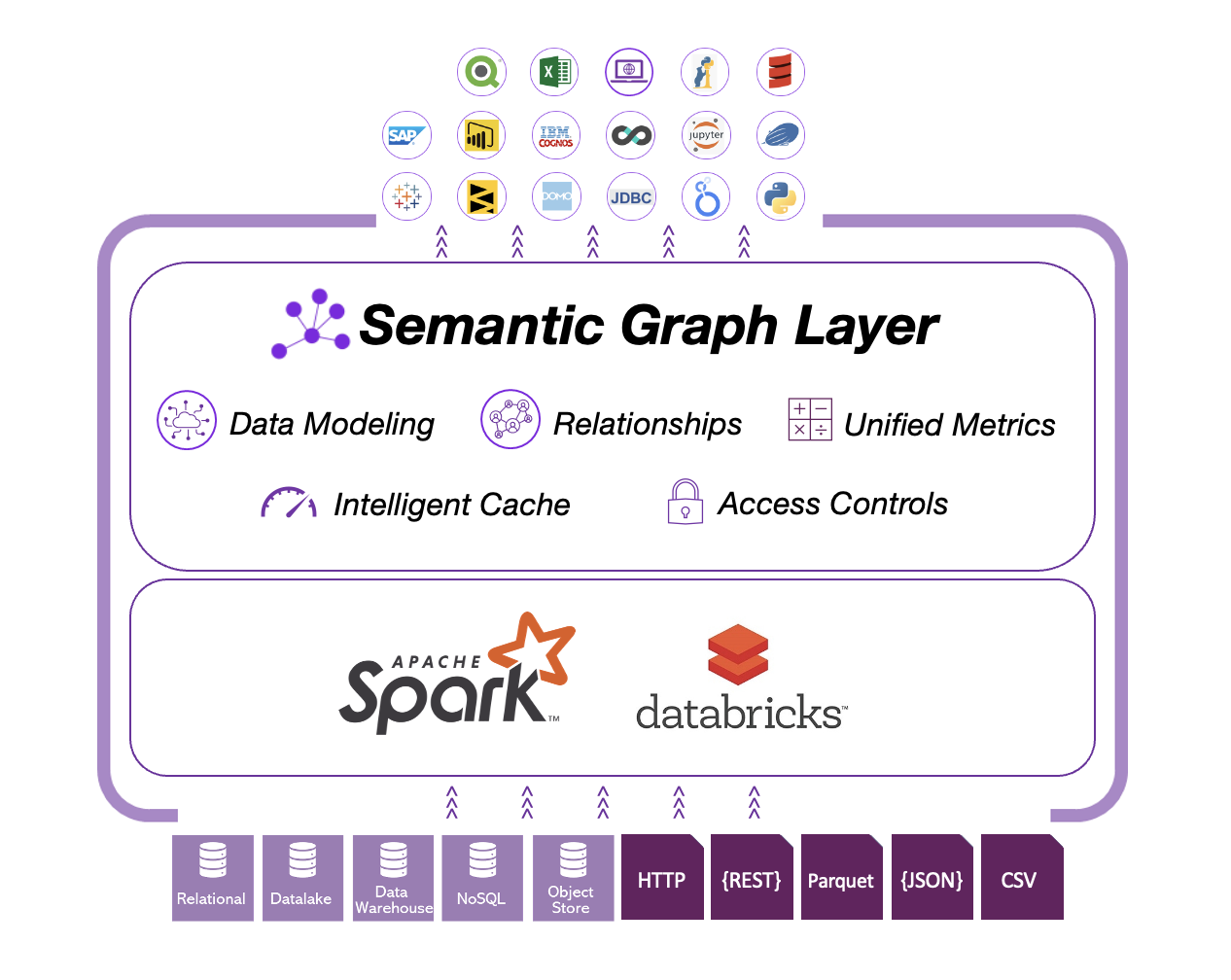
Data Virtualization
Timbr’s data virtualization joins multiple data sources at scale, so users can conveniently consume distributed/siloed data represented as a single semantic graph that can be queried with short and simple SQL queries.
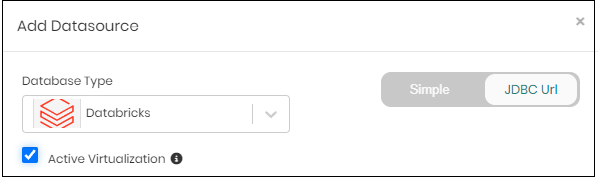
When adding a Databricks datasource you can activate the virtualization option. This option is exclusive to Databricks and Spark clusters only.
You can set it up when creating a Databricks datasource:
Or configure it on an existing datasource:

In these examples, you’ll find guided explanations demonstrating how to query multiple datasources when virtualization is enabled: