Apache Hive
Apache Hive is a data warehouse infrastructure built on top of Hadoop that provides data summarization, query, and analysis. Hive allows users to query large datasets stored in Hadoop using a SQL-like language called HiveQL, which is automatically converted to MapReduce, Apache Tez, or Spark jobs.
![]()
Integrating Apache Hive with Timbr allows you to leverage Timbr's semantic graph capabilities while maintaining Hive's powerful data processing features. This integration enables advanced features like semantic querying, data virtualization, and integrated data management, providing powerful insights and efficiencies.
Getting Started with Apache Hive
If you haven't yet set up Apache Hive, follow these steps to get started:
To connect Timbr to your Apache Hive datasource, you need to use the Apache Hive JDBC driver. For information on the Hive JDBC driver and how to set it up, refer to the Apache Hive JDBC Driver documentation.
Connecting Timbr to Apache Hive in the Timbr Platform
Once you've set up Apache Hive and have the JDBC driver ready, it's time to connect Timbr to Hive. Follow the steps below for a detailed tutorial on connecting Timbr to Apache Hive:
Navigate to Manage Datasources: From the Timbr interface, click on the Manage tab and select Datasources.
Add New Datasource: On the top right, click the Add New Datasource button. Alternatively, you can click the big add button beneath the knowledge graphs and datasources tabs.

- Fill in Connection Details: A pop-up window will appear where you need to provide the relevant connection details to connect Apache Hive to Timbr.
There are two options in Timbr to enter the connection information: Simple or JDBC Url.
On the top right of the pop-up window , the toggle can be switched from Simple to JDBC Url in order to connect the datasource using the relevant JDBC URL.

Simple Tab Connection Configuration
Select Simple Tab: Ensure the Simple tab is selected.
Fill in the Following Details:
- Database Type: Select Apache Hive.
- Datasource Name: Enter a name for your datasource.
- Description: Provide a description of the datasource (Optional).
- Hostname / IP: Enter the hostname or IP address of your Apache Hive datasource.
- Port: Default is 10000.
- Username: Enter your Apache Hive username.
- Password: Enter your Apache Hive password.
- Additional Parameters: Add any additional connection parameters using
;as separators.
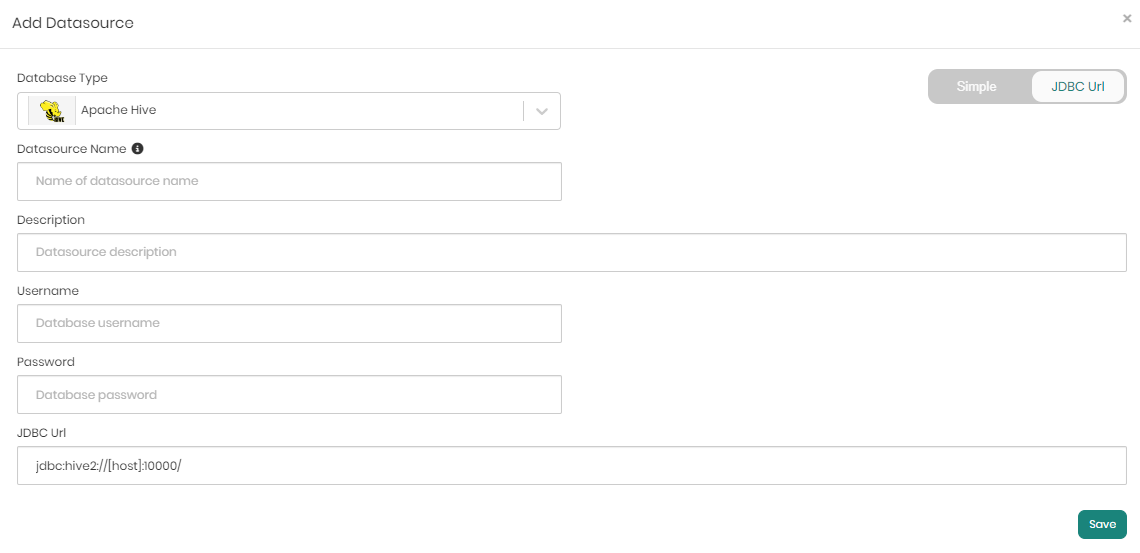
JDBC URL Tab Configuration
Select JDBC URL Tab: Ensure the JDBC URL tab is selected.
Fill in the Following Details:
- Database Type: Select Apache Hive.
- Datasource Name: Enter a name for your datasource.
- Description: Provide a description of the datasource (Optional).
- Username: Enter your Apache Hive username.
- Password: Enter your Apache Hive password.
- JDBC URL: Enter the JDBC connection URL (e.g.,
jdbc:hive2://[hostname]:port/).
Save and Test Connection
- After entering the details, click the Save button to save the information, connecting the Apache Hive datasource to the Timbr environment.
- Once saved, on the top right, click the Test connection button to verify the datasource’s connectivity, ensuring it is active and responsive.
For a comprehensive guide on connecting Timbr to various datasources, refer to the detailed documentation: